Einführung zu pandas#
pandas ist eine Open-Source Python-Bibliothek zur Arbeit mit und Analyse von tabellarischen Daten sowie Zeitreihen und bietet dafür umfangreiche Funktionalitäten. pandas basiert auf zwei primären Datenstrukturen:
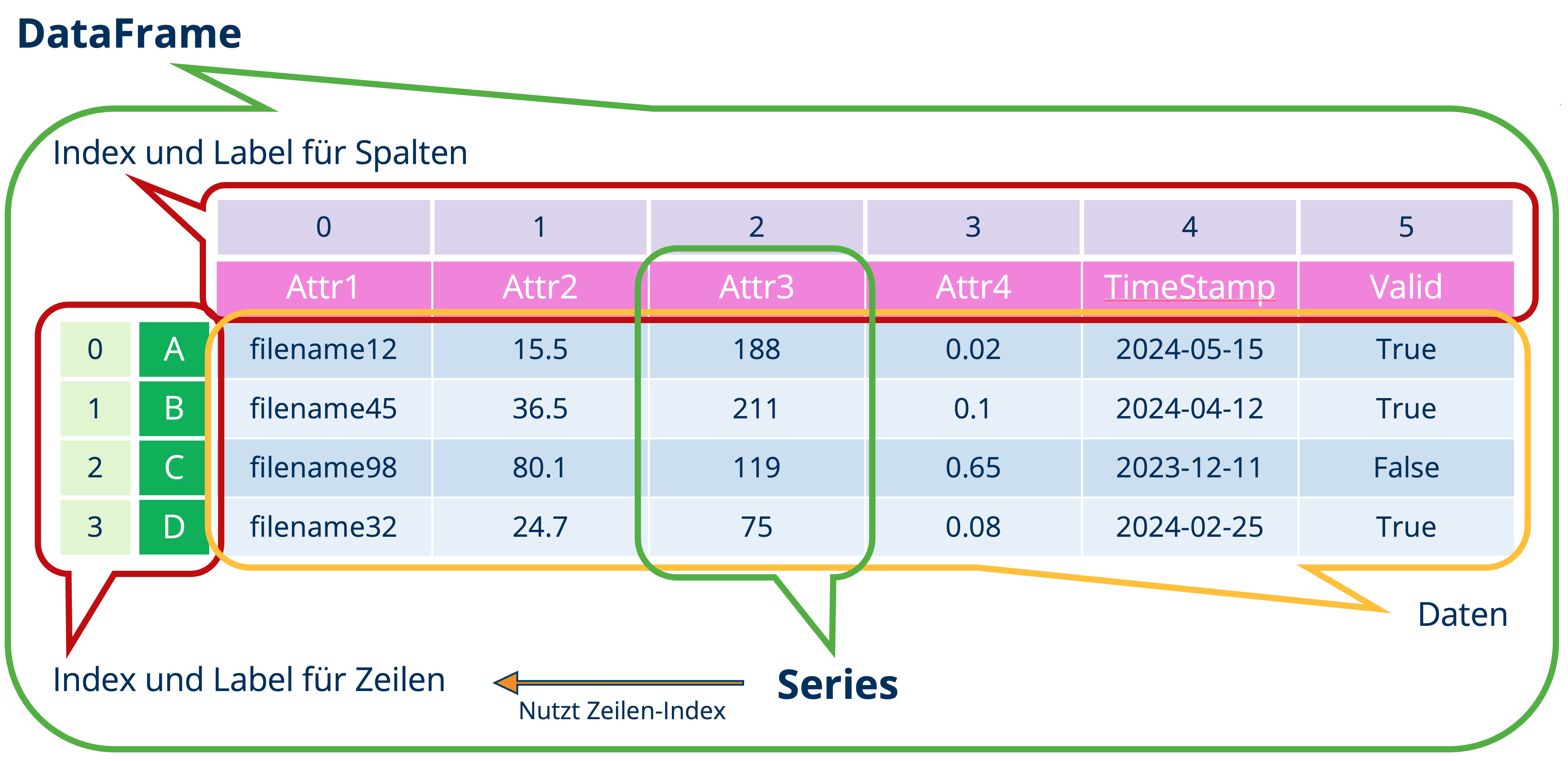
Series (1-dimensionales Array mit Index und Label, d.h. eine einspaltige Tabelle)
DataFrame (2-dimensionale tabellarische Datenstruktur mit Index und Label)
Einen guten Überblick und Einstieg bietet das 10-Minuten-Tutorial zu Pandas.
Alternativen#
Während pandas derzeit als de-facto Standard für die allgemeine Analyse tabellarischer Daten in Python mit großer Kompatibilität zu anderen Python Bibliotheken gesehen werden kann, gibt es im Python Ökosystem aber auch zahlreiche Alternativen, die je nach Anwendungsfall ihre Vor- und Nachteile haben. Die meisten erweitern pandas bzw. bieten eine ähnliche Handhabung. Zwei Beispiele:
Dask für pararelle Datenanalyse von sehr großen Datenmengen (larger-than-memory), hohe Kompatibilität zu anderen KI/ML-Tools
Polars für hochperformante Datenanalyse, Handhabung unterscheidet sich zu pandas, zunehmende Kompatibilität zu anderen Tools
# pandas importieren
import pandas as pd
Erstellen von DataFrames#
Angenommen, wir haben ein Python Dictionary mit Textdaten für die weitere Analyse. Diese Daten können leicht in einen DataFrame übertragen werden.
data_dict = {
'entry': ['A', 'B', 'C'],
'text': ['this is text', 'this is another text', 'this is another, but even longer text'],
'author': ['author1', 'author2', 'author3'],
'date': ['2024-12-01', '2024-12-15', '2024-12-31']
}
df = pd.DataFrame(data=data_dict)
Die Daten werden in ein Objekt vom Typ DataFrame geladen und in der Variable df gespeichert.
print(type(df))
<class 'pandas.core.frame.DataFrame'>
Exploration von DataFrames#
Ein DataFrame stellt umfangreiche Methoden zur Bearbeitung und Analyse seiner Daten bereit - z.B. um zunächst grundlegende Informationen zu den Daten zu erhalten.
# Ausgabe von Metadaten
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 entry 3 non-null object
1 text 3 non-null object
2 author 3 non-null object
3 date 3 non-null object
dtypes: object(4)
memory usage: 228.0+ bytes
# Ausgabe der ersten n Zeilen
df.head(2)
| entry | text | author | date | |
|---|---|---|---|---|
| 0 | A | this is text | author1 | 2024-12-01 |
| 1 | B | this is another text | author2 | 2024-12-15 |
# Ausgabe der letzten n Zeilen
df.tail(2)
| entry | text | author | date | |
|---|---|---|---|---|
| 1 | B | this is another text | author2 | 2024-12-15 |
| 2 | C | this is another, but even longer text | author3 | 2024-12-31 |
# Ausgabe beschreibender Statistiken
df.describe().transpose()
| count | unique | top | freq | |
|---|---|---|---|---|
| entry | 3 | 3 | A | 1 |
| text | 3 | 3 | this is text | 1 |
| author | 3 | 3 | author1 | 1 |
| date | 3 | 3 | 2024-12-01 | 1 |
Wir können alternativ auch den KI-Assistenten biabob nutzen, um Informationen über den DataFrame zu erhalten.
Der KI-Assistenten muss für jedes Notebook neu importiert und initialisiert werden. Der API-Key muss allerdings nicht mehr angegeben werden, da er automatisch aus der conda Umgebungsvariablen ausgelesen wird (siehe 0_prepare/1_test-ai.ipynb).
# Import und Initialisierung von bia-bob
from bia_bob import bob
# API Key wird aus condas Umgebungsvariable gelesen
bob.initialize(endpoint='blablador', model='alias-fast')
%%bob
Analysiere den Inhalt des DataFrame {df} und beschreibe ihn mir im Detail, gib mir auch Informationen zu den Datentypen. Kein Code, antworte in Deutsch
Der DataFrame enthält drei Spalten: “entry”, “text” und “author”, mit jeweils einer Zeile pro Datensatz. Hier ist eine detaillierte Analyse des Inhalts des DataFrames:
Spalte “entry”:
Diese Spalte scheint eine Art Identifier oder Kategorie für die Einträge zu sein.
Die Werte in dieser Spalte sind einfache Zeichenketten (“A”, “B”, “C”) und könnten als ID oder Bezeichner für die einzelnen Einträge dienen.
Spalte “text”:
Diese Spalte enthält den eigentlichen Textinhalt.
Die Werte in dieser Spalte sind ebenfalls Zeichenketten, die unterschiedliche Längen aufweisen.
Der Text in der ersten Zeile lautet “this is text”, in der zweiten Zeile “this is another text”, und in der dritten Zeile “this is another, but even longer text”.
Spalte “author”:
Diese Spalte enthält den Namen des Autors, der den jeweiligen Text verfasst hat.
Die Werte in dieser Spalte sind Zeichenketten und könnten als Name des Autors dienen.
Der Autor der ersten Zeile ist “author1”, der der zweiten Zeile ist “author2”, und der der dritten Zeile ist “author3”.
Spalte “date”:
Diese Spalte enthält das Datum, an dem der Text verfasst wurde.
Die Werte in dieser Spalte sind ebenfalls Zeichenketten im Format “YYYY-MM-DD”.
Die Daten sind “2024-12-01”, “2024-12-15”, und “2024-12-31”.
Auswahl und Filtern#
Ähnlich wie bei Sequenz-Typen in Python (z.b. Liste), können wir auch bei DataFrames mittels Indexing, Slicing und Masking bestimmte Teile der Daten auswählen und abrufen. Siehe dazu auch der pandas User Guide Indexing and selecting data.
Auswahl von Spalten und Zeilen#
Wir können uns zunächst weitere Informationen zum Index der Spalten (columns) und der Zeilen (index) ausgeben lassen.
df.columns
Index(['entry', 'text', 'author', 'date'], dtype='object')
df.index
RangeIndex(start=0, stop=3, step=1)
In diesem Fall wurde von pandas für die Zeilen ein einfacher fortlaufender Index (range) beginnend bei 0 gesetzt, da wir beim Erstellen des DataFrame keine anderen Vorgaben gemacht haben.
Wir können den aktuellen Index aber auch gegen einen Eigenen ersetzen - hier gegen die Werte in der Spalte entry. Das Ergebnis speichern wir in einem neuen DataFrame.
df_new = df.set_index('entry')
df_new.index
Index(['A', 'B', 'C'], dtype='object', name='entry')
Label-basierte Auswahl#
Um Spalten des DataFrame auszuwählen, nutzen wir den [] Operator - dieser erwartet die Angabe eines Label (Name einer Spalte).
df_new['text']
entry
A this is text
B this is another text
C this is another, but even longer text
Name: text, dtype: object
Die zurückgebene Datenstruktur ist eine Series (siehe Abbildung oben) - diese beinhaltet das Label und die Daten der Spalte sowie den Index der Zeilen.
print(type(df_new['text']))
<class 'pandas.core.series.Series'>
Wir können auch mehrere Spalten auswählen, indem wir eine Liste von Labels übergeben. Das Ergebnis können wir auch in eine neue Variable speichern.
result = df_new[['date', 'text']]
Frage: welchen Inhalt und welchen Typ hat result?
# print(...)
Sehen wir uns nun den Index der Zeilen näher an.
Wenn wir bestimmte Zeilen auswählen wollen, verwenden wir die Methode loc[]. Auch loc[] funktioniert nur mit Labels, nun mit den Labels der Zeilen.
df_new.loc['A']
text this is text
author author1
date 2024-12-01
Name: A, dtype: object
Auch hier lassen sich mehrere Zeilen auswählen, indem eine Liste von Labels übergeben wird.
df_new.loc[['A', 'C']]
| text | author | date | |
|---|---|---|---|
| entry | |||
| A | this is text | author1 | 2024-12-01 |
| C | this is another, but even longer text | author3 | 2024-12-31 |
Frage: Welchen Typ haben die Rückgaben von loc[]?
# print(...)
Mit loc[] können wir zudem die Label-basierte Auswahl von Zeilen und Spalten kombinieren:
df_new.loc[['A','B'], ['date', 'text']]
| date | text | |
|---|---|---|
| entry | ||
| A | 2024-12-01 | this is text |
| B | 2024-12-15 | this is another text |
Mit dem Slicing Operator : können wir für die Auswahl auch Bereiche (von : bis) angeben, dabei ist aber die reale Reihenfolge der Label zu beachten:
# Wähle alles bis einschließlich Zeile 'B' und ab Spalte 'author'
df_new.loc[:'B', 'author':]
| author | date | |
|---|---|---|
| entry | ||
| A | author1 | 2024-12-01 |
| B | author2 | 2024-12-15 |
# Wähle alles von Zeile 'C' bis Zeile 'A' - gibt kein Ergebnis, da nicht-existente Reihenfolge
df_new.loc['C':'A']
| text | author | date | |
|---|---|---|---|
| entry |
Integer-basierte Auswahl#
Wenn wir Daten auf Basis der Index-Positionen auswählen wollen, nutzen wir iloc[], hierbei stellen wir die Integer-Positionen der gewünschten Indizes bereit. Auch mit iloc[] können Zeilen und Spalten zeitgleich ausgewählt werden und es wird Slicing via : unterstützt.
# Auswahl der ersten Zeile, gezählt wird ab 0
df_new.iloc[0]
text this is text
author author1
date 2024-12-01
Name: A, dtype: object
Übung#
Gib mittels iloc[] die Daten aus der ersten und dritten Zeile aus, dabei aber nur die ersten beiden Spalten
# df_new.iloc[...]
Boolean Indexing#
Mittels Boolean Indexing (auch Masking) können wir bestimmte Teile der Daten auf der Grundlage von bedingten/logischen Abfragen auswählen, wenn wir die Operatoren [] oder loc[] nutzen.
Angenommen, wir möchten alle Einträge für einen bestimmten Autoren-Namen erhalten.
# Erstellen einer entsprechenden Boolean Mask
mask = df_new['author'] == 'author1'
mask
entry
A True
B False
C False
Name: author, dtype: bool
# Anwenden der Mask auf den DataFrame: df_new[mask]
# Oder als Einzeiler
df_new[df_new['author'] == 'author1']
| text | author | date | |
|---|---|---|---|
| entry | |||
| A | this is text | author1 | 2024-12-01 |
Mit loc[] können wir die Auswahl zudem auf bestimmte Spalten beschränken
df_new.loc[df_new['author'] == 'author1', ['text', 'author']]
| text | author | |
|---|---|---|
| entry | ||
| A | this is text | author1 |
Übung#
Logische Abfragen können auch kombiniert und mit Methoden erweitert werden. Nutze den KI-Assistenten, um folgende Daten auszuwählen:
Alle Einträge, die entweder von “author1” stammen, oder deren Inhalt in “text” mehr als 4 Wörter hat.
%%bob